1. The goal of ICA
Welcome to the International Corpus of Arabic website of Bibliotheca Alexandrina. Bibliotheca Alexandrina (BA) is one of the leading international organizations in Egypt that took it upon itself to play its part in the disseminating of culture and knowledge, as well as supporting scientific research. It has initiated an enormous project of building the International Corpus of Arabic (ICA) as an ambitious attempt to build a representative corpus of the Arabic language as it is used all over the Arab world, with the aim of supporting research on such language. The ICA is planned to contain 100 million words. Once finished, the analyzed version will be the first analyzed Arabic corpus available as a linguistic resource for researchers. It is also the first systematic investigation of national varieties within the Arabic speaking community, this should prove very useful for linguists who believe that their theories and descriptions of language should be based on real, rather than contrived, data.
2. Planning the construction of ICA
In planning the collection of texts for the ICA, a number of decisions related to corpus design such as representativeness, diversity, balance and size were taken into consideration.
In collecting a representative corpus of the Arabic Language, the main focus was to cover the same genres from different sources and from all around the Arab world. Hence, the ICA covers numerous sources (Newspapers, web articles, books.. etc.) and numerous genres (Literature, Politics, Sciences..etc.).
The design chosen was to break up the corpus into the different sources, and subsequently break up these sources into the various genres they comprise. In addition, a careful record of a variety of variables is kept with every text; when and where the text was written and published, its source and its genre (Meta information data).
Decisions related to what the proportions (weighting) between different sections and genres in a corpus have been taken. Such decisions were taken upon how common the genre or the source is (Balance in a corpus is not addressed by having equal amounts of text from different sources and genres).
Decisions about how many categories the corpus should contain, how many samples the corpus should contain in each category and how many words there should be in each sample were taken into consideration. Some discussions of the size in the corpus design focused exclusively on the number of words in the corpus, However, issues of size also relate to the number of texts from different categories, the number of samples from each text, and the number of words in each sample.
3. ICA Design
-
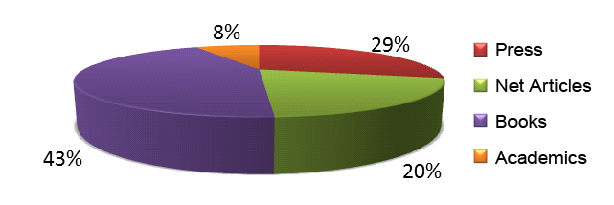
There are 4 sources all over the corpus, namely; Press, Net articles, Books and Academics.
-
The press source is divided into three sub-sources, namely; Newspapers, Magazines, Electronic Press.
-
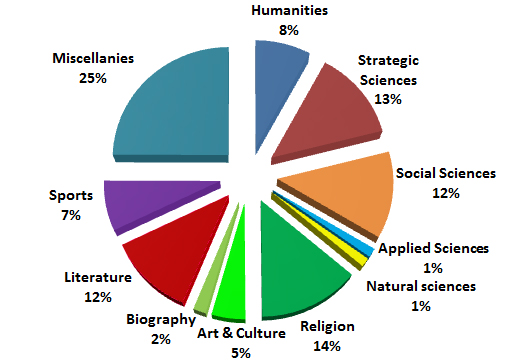
There are 11 genres all over the corpus, namely; Strategic Sciences, Social Sciences, Sports, Religion, Literature, Humanities, Natural Sciences, Applied Sciences, Art, Biography and Miscellaneous.
-
There are 24 sub-genres, namely; Politics, Law, Economy, Sociology, Islamic, Christian, Other religions, Comparative religion, prose, Poetry, Studies of Literature and Linguistic, History, Psychology, Philosophy, Geography, Biology, Physics, Chemistry, Geology and Environment, Space, Medicine, Engineering, Agriculture and Technology.
-
There are 4 sub-sub-genres, namely; Novels, Short Stories, Child Stories and plays.
-
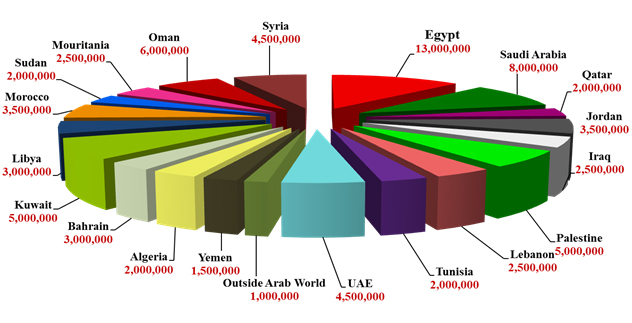
All the publications of the Arab world have been covered in addition to some of the texts published outside the Arab world.
4. ICA Analysis stage
Currently, this stage includes the morphological analysis of each word within the corpus, the analysis was done automatically using both statistical and rule based approach depending on one of the famous Arabic morphological Analyzers "Tim Buckwalter"; where the analysis lists number of information such as Prefix(s), Suffix(s), Word Class, Stem, Lemma, Root, Stem Pattern as well as Number, Gender and Definiteness according to the different contexts of the words within the corpus.